昨年、データサイエンティスト協会主催のデータサイエンティスト養成講座を受講し、その中でRを使ったデータ分析手法を学んだのでその復習兼ねてまとめておきます。
(参考:データサイエンティスト養成講座)
https://www.datascientist.or.jp/news/ds-training-program201909/

目次
1.概要
データ分析コンテストで有名なKaggleの日本版とも呼ばれるSIGNATEのデータ分析問題を扱います。
- 銀行の定期預金申込キャンペーンについてキャンペーンデータから結果(定期預金のために口座開設したか)を予測する。


<背景と目的>
銀行の定期預金申込キャンペーンについて、その効果を測定したい。
具体的には、どのような顧客にどのようなアプローチでキャンペーンを打つとより効果的に定期預金申込に繋がるのかを分析したい。
そのためにキャンペーンデータから実際に定期預金申込に至るかどうかを予測するモデルを構築する。
2.データセット
使用するデータは、27,128名の顧客データとキャンペーンの結果(定期預金申込の有無)データ。
最終的にコンペで予測するのは、18,083名のキャンペーンに対する反応(結果)。

| カラム | 型 | 説明 |
| id | int | id |
| age | varchar | 年齢 |
| job | varchar | 職種 |
| martial | varchar | 未婚/既婚(divorced / married / single) |
| education | varchar | 教育水準(primary / secondary / tertiary) |
| default | varchar | 債務不履行の有無(yes / no) |
| balance | int | 保有資産 |
| housing | varchar | 住宅ローン(yes / no) |
| loan | varchar | 個人ローン(yes / no) |
| contact | varchar | 連絡方法(cellular / telephone) |
| day | int | 最終接触日 |
| month | char | 最終接触月 |
| duration | int | 最終接触時間(秒) |
| campaign | int | 現在のキャンペーン中の接触回数 |
| pdays | int | 前回のキャンペーン接触日からの経過日数 |
| previous | int | 前回のキャンペーンまでの接触実績 |
| poutcome | varchar | 前回のキャンペーンの実績(success / failure / other) |
| y | boolean | 定期預金の申込結果(1:成約、0:非成約) |

使ったコマンド
nrow
使用目的:行数カウント
使用方法:nrow(dataframe)
nrow(train_data)) [1] 27128

3.データ分析
まず、学習データ全体での成約率(陽性率)を確認する。
train_data <- dplyr::group_by(train_data,y) dplyr::summarise(train_data,n=n()) dplyr::ungroup(train_data)

27128件中、成約に至った(y:1)のは3174件で、全体の11.7%
次に説明変数の確認のため、離散変数についてその値ごとに成約率(陽性率)を確認する。
・job( 職種)ごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,job) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉成約率(mean)が高いのは、student(学生)、retired(退職者)、management(経営者)、admin(管理職)で、学生、高齢者、失業者、富裕者となった。
👉成約率が低いのは、blue-color(肉体労働者)、services(サービス業)、entrepreneur(企業家)、housemaid(家政婦)で低所得層となった。
並び替えると以下の通り。

使ったコマンド
group_by
使用目的:データフレームを指定した変数でグループ化する
使用方法:dplyr::group_by(dataframe,column)
summarise
使用目的:表の集計
使用方法:dplyr::summarise(dataframe,任意の集計処理)
同様にして、
・matiral(未婚/既婚)ごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,marital) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉大きな差は見られないが、single(独身)がやや高めの傾向。
・education(教育水準)ごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,education) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉primary(初等教育)ほど成約率は低く、secondary(中等教育)、teritary(三次教育、高等教育)と高度になるほど成約率が高くなる傾向。
👉unknownは欠損値のため削除するか補充するか処理が必要となる。
・defaulごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,default) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉no(債務不履行なし)の方が、yes(債務不履行あり)よりも成約率は高い
・housing(住宅ローン)ごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,housing) dplyr::summarise(train_g1,n=n(),mean=mean(y))
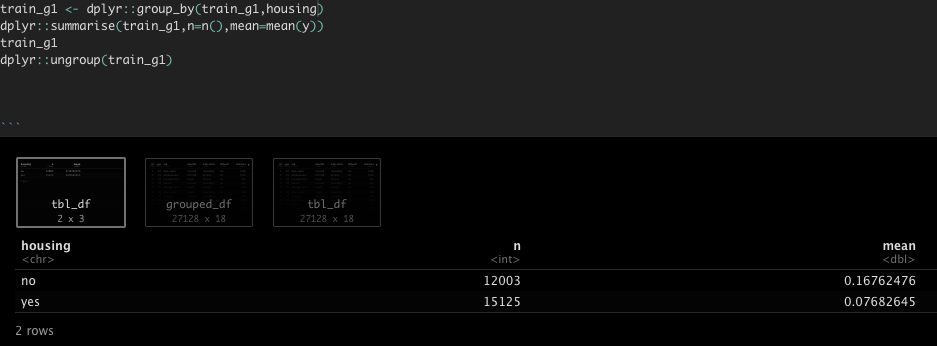
👉no(住宅ローンなし)の方が、yes(住宅ローンあり)よりも成約率が高い傾向
・loanごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,loan) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉no(個人ローンなし)の方が、yes(個人ローンあり)よりも成約率が高い傾向
・contactごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,contact) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉cellular(携帯)の方が絶対数が多いが、成約率とはあまり相関はなさそう
・poutcome(前回実績)ごとの成約率
train_g1 <- train_data train_g1 <- dplyr::group_by(train_g1,poutcome) dplyr::summarise(train_g1,n=n(),mean=mean(y))

👉圧倒的にsuccess(前回実績も成功)の場合に成約率が高いが、unknownのデータが多いのでそのままでは利用し難い
さらに、変数間の相関を確認する。
cor(train_data)
使ったコマンド
cor
使用目的:相関係数の確認
使用方法:cor(dataframe) ※表全体、cor(x,y,z)※変数指定

👉ただし、今のままだと文字型の変数が含まれているためエラーになるのでいったん数値型変数に絞って実施してみる
👉まず数値型の変数のみ抽出した別のデータフレームを作成してから相関行列を作成する
str(train_data)
list <- c("age","balance","day","duration","campaign","pdays","previous","y")
train_1 <- train_data[,list]
train_1
cor1 <- cor(train_1)
cor1



👉balance(資産)とage、campaign(接触回数)とday(最終接触日)、previous(接触実績)とpdays(接触日からの経過日数)、y(成約に至ったか)とduration(接触時間)には正の相関が見られる
👉pdays(接触日からの経過日数)とday(最終接触日)には弱い負の相関が見られる
この後、前処理(変数加工)してアルゴリズム構築して実際の分析と評価になりますが、少し長くなったので別記事で。
以上
続きは以下


